Two important questions we would like to settle about likelihood analysis are
(a) is the method optimal in the sense that we get the minimum variance
(smallest error bars) for a given amount of data? and (b) is the method
efficient -- can we realistically find the best-fitting parameters? As an
example of this last point, if we have  data points (pixels, harmonic
coefficients, etc), and
data points (pixels, harmonic
coefficients, etc), and 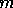 parameters to estimate with a sampling rate of
parameters to estimate with a sampling rate of
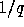 , we find that the calculation time scales as
, we find that the calculation time scales as

where the first term is just the total number of points at which we need to
calculate the likelihood, and the second term is the time that it takes to
calculate the inverse of 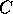 and its determinant. Of course, in practice one
would not find the maximum likelihood solution this way, but it serves to
illustrate the point. Note that the covariance matrix depends on the parameters
and therefore must be evaluated locally in parameter space. For MAP or Planck
we have
and its determinant. Of course, in practice one
would not find the maximum likelihood solution this way, but it serves to
illustrate the point. Note that the covariance matrix depends on the parameters
and therefore must be evaluated locally in parameter space. For MAP or Planck
we have 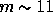 ,
, 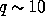 and
and 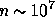 , resulting in
, resulting in 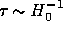 , even for nanosecond technology. But before we give up in dismay, it
is worth looking a bit further at the theory of parameter estimation.
, even for nanosecond technology. But before we give up in dismay, it
is worth looking a bit further at the theory of parameter estimation.