The analysis presented so far is strictly optimal only for the conditional
likelihood -- the estimation of one parameter when all others are known. A far
more challenging task is to optimise the data compression when all parameters
are to be estimated from the data. In this case, the marginal error on a
single parameter 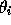 rises above the conditional error
rises above the conditional error 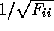 to
to 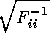 . As far as we are aware, there is no general solution
known to this problem, but here we present some methods which have intuitive
motivation and appear successful in practice.
. As far as we are aware, there is no general solution
known to this problem, but here we present some methods which have intuitive
motivation and appear successful in practice.
Suppose that we repeat the optimisation procedure, outlined above, 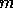 times,
once for each parameter. The union of these sets should do well at estimating
all parameters, but the size may be large. However, many of the modes may
contain similar information, and this dataset may be trimmed further without
significant loss of information. This is effected by a singular value
decomposition of the union of the modes, and modes corresponding to small
singular values are excluded. Full details are given in Tegmark, Taylor & Heavens (1997), and an
example from COBE is illustrated in Figure 1, which shows that for the
conditional likelihoods at least, the data compression procedure can work
extremely well. However, this on its own may not be sufficient to achieve
small marginal errors, especially if two or more parameters are highly
correlated. This is expected to be the case for high-resolution CMB
experiments such as MAP and Planck (e.g. for parameters
times,
once for each parameter. The union of these sets should do well at estimating
all parameters, but the size may be large. However, many of the modes may
contain similar information, and this dataset may be trimmed further without
significant loss of information. This is effected by a singular value
decomposition of the union of the modes, and modes corresponding to small
singular values are excluded. Full details are given in Tegmark, Taylor & Heavens (1997), and an
example from COBE is illustrated in Figure 1, which shows that for the
conditional likelihoods at least, the data compression procedure can work
extremely well. However, this on its own may not be sufficient to achieve
small marginal errors, especially if two or more parameters are highly
correlated. This is expected to be the case for high-resolution CMB
experiments such as MAP and Planck (e.g. for parameters 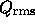 and
and
 ). To give a more concrete example -- a thin ridge of likelihood at
). To give a more concrete example -- a thin ridge of likelihood at
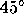 to two parameter axes has small conditional errors, but the marginal
errors can be very large. This applies whether or not the likelihood surface
can be approximated well by a bivariate Gaussian.
to two parameter axes has small conditional errors, but the marginal
errors can be very large. This applies whether or not the likelihood surface
can be approximated well by a bivariate Gaussian.
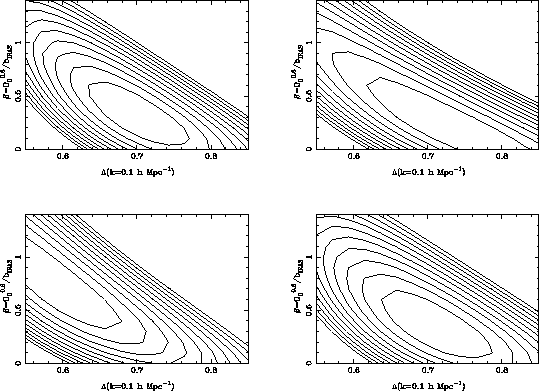
Figure 2: Illustration of data compression with different
algorithms. Top left: `Full' dataset of 508 modes (for details of parameters
etc, see text). Top right: Best 320 modes optimised for measuring 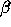 .
Bottom left: Best 320 modes from SVD application to modes optimised for
.
Bottom left: Best 320 modes from SVD application to modes optimised for 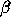 and
and 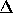 . Bottom right: Best 320 modes for optimising along the likelihood
ridge axis. Likelihood contours are separated by 0.5 in natural log.
. Bottom right: Best 320 modes for optimising along the likelihood
ridge axis. Likelihood contours are separated by 0.5 in natural log.
This latter case motivates an alternative strategy, which recognises that the
marginal error is dominated not by the curvature of the likelihood in the
parameter directions, but by the curvature along the principal axis of the
Hessian matrix with the smallest eigenvalue. Figure 2 shows how
various strategies fare with a simultaneous estimation of the amplitude of
clustering 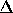 and the redshift distortion parameter
and the redshift distortion parameter 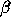 , in a
simulation of the PSCz galaxy redshift survey. The top left panel shows the
likelihood surface for the full set of 508 modes considered for this analysis
(many more are used in the analysis of the real survey). The modes used, and
indeed the parameters involved, are not important for the arguments here. We
see that the parameter estimates are highly correlated. The second panel, top
right, shows the single-parameter optimisation of the first part of this paper.
The modes are optimised for
, in a
simulation of the PSCz galaxy redshift survey. The top left panel shows the
likelihood surface for the full set of 508 modes considered for this analysis
(many more are used in the analysis of the real survey). The modes used, and
indeed the parameters involved, are not important for the arguments here. We
see that the parameter estimates are highly correlated. The second panel, top
right, shows the single-parameter optimisation of the first part of this paper.
The modes are optimised for 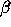 , and only the best 320 modes are used. We
see that the conditional error in the
, and only the best 320 modes are used. We
see that the conditional error in the 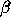 direction is not much worse than
the full set, but the likelihood declines slowly along the ridge, and the
marginal errors on both
direction is not much worse than
the full set, but the likelihood declines slowly along the ridge, and the
marginal errors on both 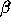 and
and 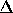 have increased substantially. In
the panel bottom left, the SVD procedure has been applied to the union of modes
optimised for
have increased substantially. In
the panel bottom left, the SVD procedure has been applied to the union of modes
optimised for 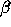 and
and 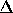 , keeping the best 320 modes. The procedure
does reasonably well, but in this case the error along the ridge has increased.
The bottom right graph shows the result of diagonalizing the Fisher matrix and
optimising for the eigenvalue along the ridge. We see excellent behaviour for
the best 320 modes, with almost no loss of information compared with the full
set. This illustrative example shows how data compression may be achieved
with good results by application of a combination of rigorous optimisation and
a helping of common sense.
, keeping the best 320 modes. The procedure
does reasonably well, but in this case the error along the ridge has increased.
The bottom right graph shows the result of diagonalizing the Fisher matrix and
optimising for the eigenvalue along the ridge. We see excellent behaviour for
the best 320 modes, with almost no loss of information compared with the full
set. This illustrative example shows how data compression may be achieved
with good results by application of a combination of rigorous optimisation and
a helping of common sense.